Oltre i pappagalli statistici: come il Machine Learning potenzia le lingue e la comunicazione – prof. Lis

Machine learning per la comunicazione, per creare contenuti e per valutarne l’operato? Sì, con la padronanza di linguaggio e lettura del contesto dei professionisti umani.
Di Mateusz Miroslaw Lis, docente di Abilità informatiche e machine learning (Classe di Laurea L-12) e IA applicata al doppiaggio, adattamento testi e sottotitolazione (Classe di Laurea LM-94)
INTELLIGENZA ARTIFICIALE VS MACHINE LEARNING
Negli ultimi anni, termini come Intelligenza Artificiale e Machine Learning sono entrati con prepotenza nel linguaggio comune, spesso utilizzati come sinonimi, ma con significati in realtà distinti.
L’Intelligenza Artificiale rappresenta un campo di ricerca molto ampio. Mira a sviluppare sistemi in grado di simulare processi cognitivi tipicamente umani: ragionamento, apprendimento, comprensione linguistica, creatività.
All’interno di questo vasto dominio, il Machine Learning costituisce una delle discipline più centrali e operative. Esso si basa sull’idea che le macchine possano “imparare” automaticamente dai dati, riconoscendo pattern e regolarità statistiche, senza che ogni regola debba essere esplicitamente programmata.
Se l’IA definisce l’obiettivo generale (cioè creare sistemi capaci di comportamenti intelligenti), il Machine Learning rappresenta il primo mezzo pratico attraverso cui tali comportamenti vengono costruiti, tramite modelli che apprendono da esempi, esperienze e grandi quantità di informazioni.
All’interno di questo vasto contesto, l’attuale rivoluzione tecnologica legata ai modelli generativi viene spesso descritta come un processo di “automazione intelligente” capace di sostituire in breve tempo l’intervento umano. Nulla di più sbagliato.
INTERVENTO UMANO SOSTITUIBILE? NON PROPRIO
Al contrario, l’utilizzo sempre più frequente dei cosiddetti pappagalli statistici rende oggi indispensabile la presenza di professionisti che possiedano solide competenze linguistiche e comunicative, affiancate da una conoscenza, anche pratica, delle tecniche di Machine Learning proprio per la comunicazione.
È infatti proprio nella capacità di comprendere, supervisionare e valutare gli output prodotti da questi sistemi che risiede la vera competenza professionale del futuro.
Tra l’aumento esponenziale della richiesta di contenuti e la facilità di utilizzo dei Large Language Models (ChatGPT, Gemini, Qwen, etc.), i casi di testi tradotti, campagne pubblicitarie o copy generati automaticamente con evidenti problemi di tono, registro o coerenza linguistica si moltiplicano.
Di fronte a questa nuova realtà, saper implementare anche solo a livello operativo strumenti e modelli predittivi per la valutazione automatica dei testi diventa un’abilità imprescindibile. Non soltanto per i data scientist, ma anche per i professionisti “non tecnici” del linguaggio, della traduzione e della comunicazione digitale.
SISTEMI AUTOMATICI PER SISTEMI AUTOMATICI
Con l’enorme quantità di materiale da produrre quotidianamente e la crescente proliferazione di contenuti generati automaticamente, il settore della comunicazione si trova di fronte a un’esigenza inedita: disporre di sistemi, anch’essi automatizzati, capaci di misurare e garantire la qualità dei testi prodotti.
Se nel mondo della comunicazione visiva la tecnologia offre già strumenti efficaci (come mappe di salienza o modelli predittivi di attenzione visiva) per evitare errori o inefficienze comunicative, molto meno sviluppato appare invece il campo della valutazione linguistica, del copywriting e della traduzione automatica.
Eppure, proprio qui si gioca una parte cruciale della trasformazione in corso.
Il professionista contemporaneo può non solo sfruttare i modelli generativi per produrre molteplici varianti di una traduzione o di un testo pubblicitario, ma anche analizzarne in modo sistematico leggibilità, tono comunicativo e coerenza con la brand voice attraverso modelli di Machine Learning dedicati alla comunicazione.
Progetti di ricerca come READ-IT e UniversalCEFR dimostrano come sia oggi possibile addestrare modelli in grado di stimare automaticamente la leggibilità e la complessità linguistica di un testo (ad esempio il livello CEFR). Questi ed altri strumenti possono essere utilizzati non solo per monitorare la qualità delle traduzioni o dei contenuti digitali, ma anche per mantenere costante la coerenza comunicativa di un brand, evitando che testi inadatti raggiungano pubblici non allineati al target desiderato.

Didascalia: Esempio di previsione del brand voice alignment di due traduzioni
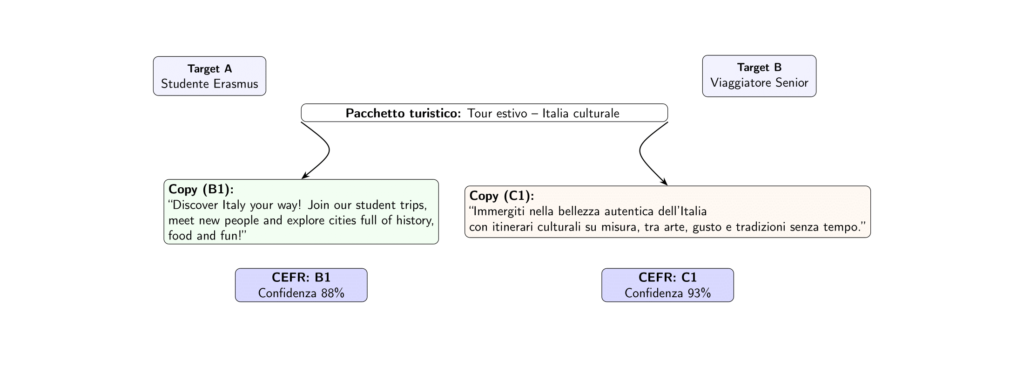
Didascalia: Esempio di previsione del livello CEFR tramite un modello di Machine Learning
In un contesto in cui la velocità di produzione tende spesso a superare la capacità umana di controllo qualitativo, l’integrazione di modelli predittivi per la valutazione linguistica rappresenta un asset strategico.
Avere a disposizione sistemi che, con rapidità e precisione, possano individuare incongruenze stilistiche o linguaggi inappropriati significa non solo ridurre il margine d’errore, ma anche rafforzare l’efficacia comunicativa complessiva di imprese, agenzie e professionisti del linguaggio, e conseguentemente la loro produttività economica.
DISCIPLINE UMANISTICHE PIÙ TECNICHE UGUALE FUTURO
La prospettiva che si apre è dunque quella di una crescente collaborazione tra discipline umanistiche e tecniche. Servono progetti di ricerca più mirati, capaci di costruire modelli specifici per ciascun settore professionale: traduzione editoriale, localizzazione, comunicazione aziendale, turismo, divulgazione scientifica.
Solo attraverso dataset accurati e annotati da esperti del linguaggio sarà possibile realizzare sistemi che comprendano davvero le sfumature del testo, il contesto culturale e la finalità comunicativa di ciascun messaggio.
Traduttori, linguisti, professionisti e studenti della comunicazione possono assumere un ruolo da protagonisti. Essi non sono più semplici utilizzatori passivi delle tecnologie, ma possono contribuire attivamente alla loro evoluzione, partecipando alla creazione di nuovi corpora, alla definizione di metriche linguistiche e alla validazione di modelli che integrino competenza umana e potenza computazionale.
La collaborazione tra ricerca accademica e professionisti del linguaggio rappresenta quindi la chiave per costruire un ecosistema in cui l’automazione non impoverisce, ma potenzia la qualità comunicativa e culturale dei nostri testi.